Introduction to VC dimension
Generalization bounds
For a hypothesis set \(\calH\) with \(\card{\calH}=M\) we showed that \[ \forall\epsilon>0\quad\P{\abs{\widehat{R}_N(h^*)-{R}(h^*)}\geq\epsilon}\leq 2M\exp(-2N\epsilon^2)\]
We used the union bound to introduced the factor \(M\); for any \(\epsilon>0\) \[\P{\abs{\widehat{R}_N(h^*)-{R}(h^*)}\geq\epsilon}\leq \P{\max_{h\in\calH}\abs{\widehat{R}_N(h)-{R}(h)}\geq\epsilon} \leq \sum_{j=1}^M\P{\abs{\widehat{R}_N(h_j)-{R}(h_j)}\geq\epsilon}\]
The second inequality is tight if the events \(\calE_j\eqdef \{\abs{\widehat{R}_N(h_j)-{R}(h_j)}\geq\epsilon\}\) are disjoint
Events are not at all disjoint when classifying
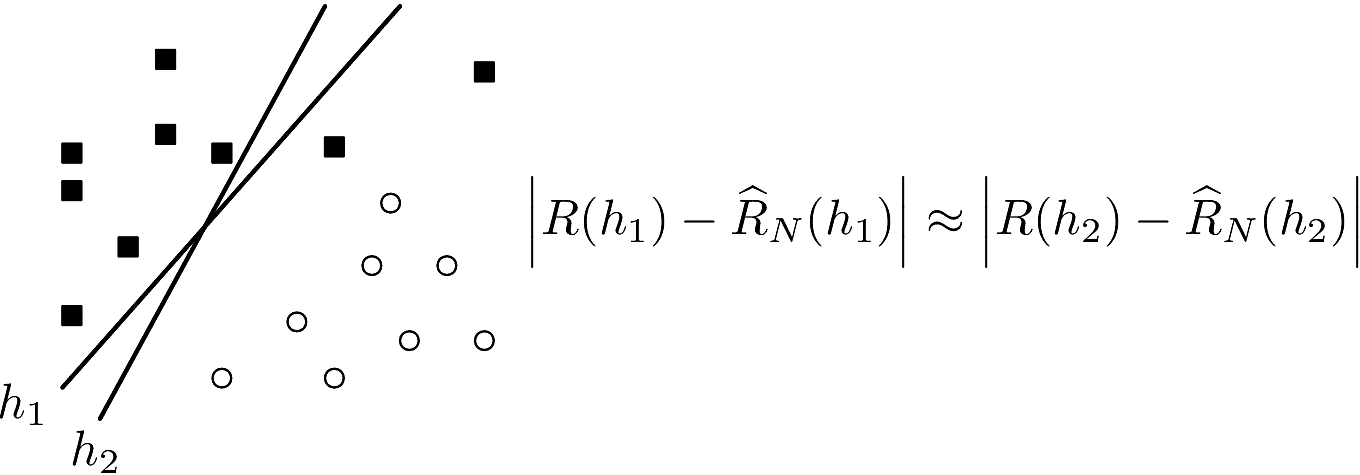
Examples
- Positive rays: \(\calH\eqdef\{h:\bbR\to\{\pm 1\}:x\mapsto \sgn{x-a}| a\in\bbR\}\)

\[m_\calH = N+1\]
Positive intervals: \(\calH\eqdef\{h:\bbR\to\{\pm 1\}:x\mapsto \indic{x\in[a;b]}-\indic{x\notin[a;b]}| a<b\in\bbR\}\)
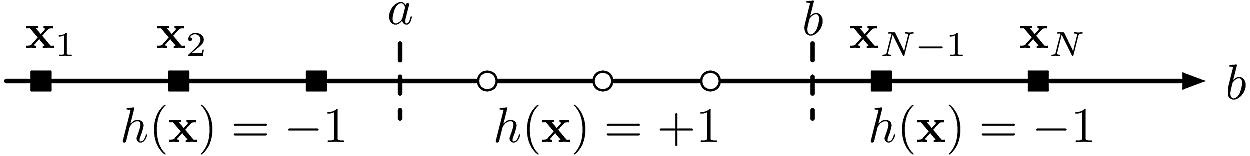
- \[m_\calH = {N+1 \choose 2}+1 = \frac{1}{2}N^2+\frac{1}{2}N+1\]
Examples
- Convex sets: \(\calH\eqdef\{h:\bbR^2\to\{\pm 1\}| \{\bfx\in\bbR^2:h(\bfx)=+1\}\textsf{ is convex}\}\)
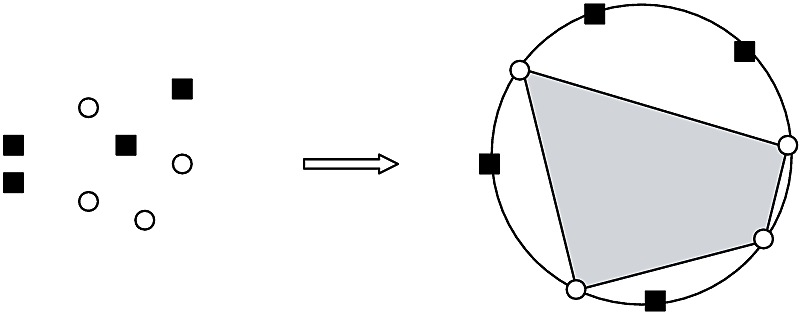
\(m_\calH(N)=2^N\) because we can generate all dichotomies
If \(\calH\) can generate all dichotomies on \(\{\bfx_i\}_{i=1}^N\), we say that \(\calH\) shatters \(\{\bfx_i\}_{i=1}^N\)
Examples
- Linear classifiers: \(\calH\eqdef\{h:\bbR^2\to\{\pm 1\}:\bfx\mapsto\sgn{\bfw^\intercal\bfx+b}| \bfw\in\bbR^2,b\in\bbR\}\)
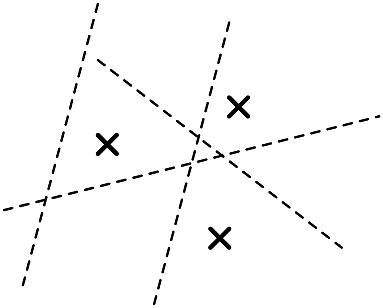
- The growth function is a worst case measure, hence \(m_{\calH}(3)=8\)

- 4 points cannot always be shattered and \(m_{\calH}(4)=14<2^4\)