Learning
Monday, December 6, 2021
Logistics
General announcements
Assignment 6 due December 7, 2021 for bonus, deadline December 10, 2021
Last lecture!
Let me know what’s missing
Expect an email from me tonight
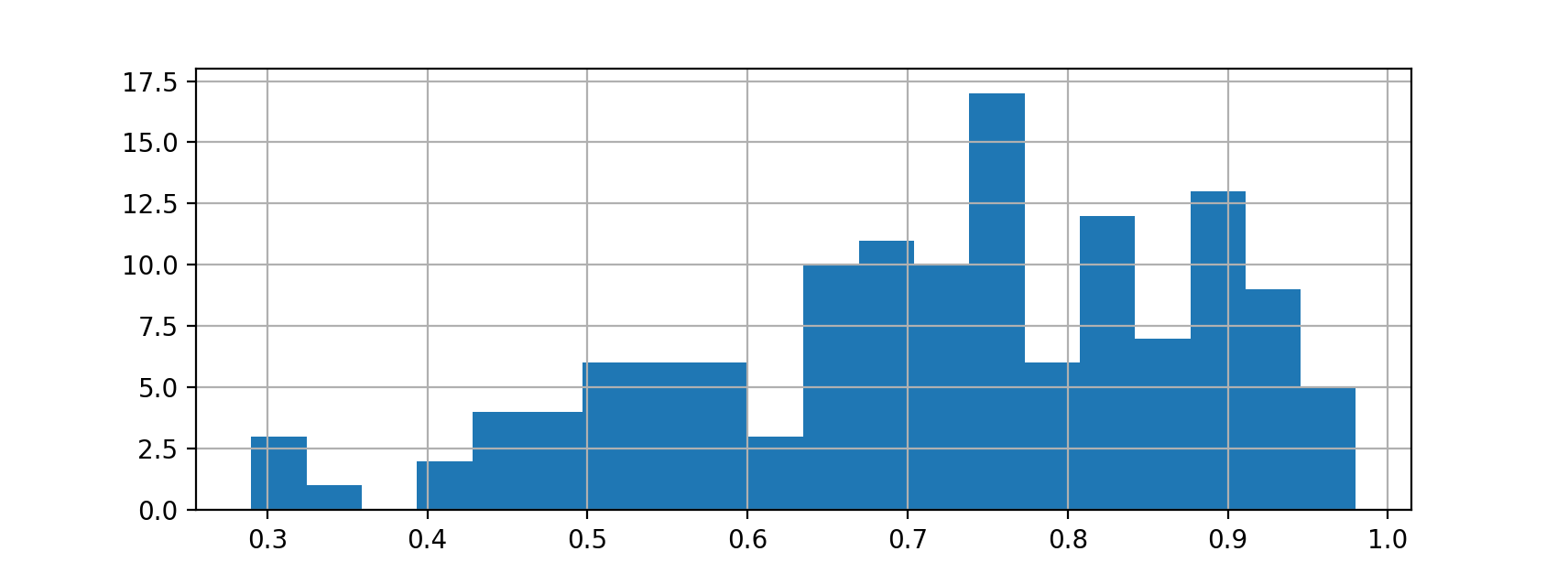
Midterm 2 statistics
- Overall: AVG: 72% - MIN: 29% - MAX: 98%
What’s on the agenda for today?

More on learning and Bayes classifiers
Lecture notes 17 and 23
Can we learn?

Our objective is to find a hypothesis \(h^*=\argmin_{h\in\calH}\widehat{R}_N(h)\) that ensures a small risk
For a fixed \(h_j\in\calH\), how does \(\widehat{R}_N(h_j)\) compares to \({R}(h_j)\)?
Observe that for \(h_j\in\calH\)
The empirical risk is a sum of iid random variables \[ \widehat{R}_N(h_j)=\frac{1}{N}\sum_{i=1}^{N} \indic{h_j(\bfx_i)\neq y_i} \]
\(\E{\widehat{R}_N(h_j)} = R(h_j)\)
\(\P{\abs{\widehat{R}_N(h_j)-{R}(h_j)}>\epsilon}\) is a statement about the deviation of a normalized sum of iid random variables from its mean
We’re in luck! Such bounds, a.k.a, known as concentration inequalities, are a well studied subject
Learning can work!
If \(\forall j\in\calH\,\abs{\widehat{R}_N(h_j)-{R}(h_j)}\leq\epsilon\) then \(\abs{R(h^*)-{R}(h^\sharp)}\leq 2\epsilon\).
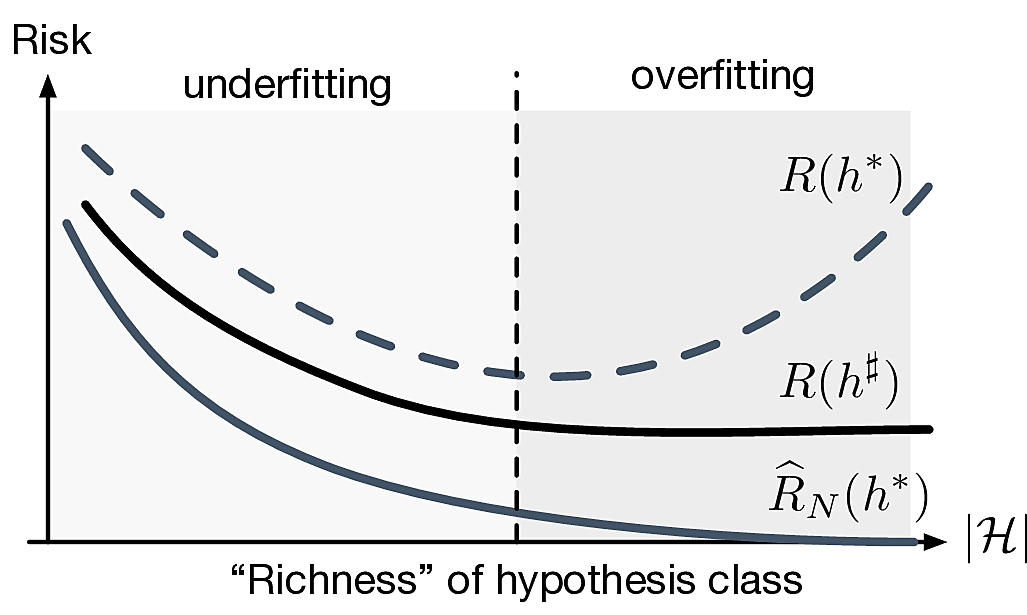
How do we make \(R(h^\sharp)\) small?
- Need bigger hypothesis class \(\calH\)! (could we take \(M\to\infty\)?)
- Fundamental trade-off of learning
What is a good hypothesis set?
Ideally we want \(\card{\calH}\) small so that \(R(h^*)\approx R(h^\sharp)\) and get lucky so that \(R(h^*)\approx 0\)
In general this is not possible
Remember, we usually have to learn \(P_{y|\bfx}\), not a function \(f\)
Questions
- What is the optimal binary classification hypothesis class?
- How small can \(R(h^*)\) be?